수익형 웹&앱 만들기 기본지식 (1) - 파이썬 설치 및 크롤링
처음으로 수익형 웹&앱을 만들어 보려고 시작하려 한다.
나만의 웹, 앱을 만드는 게 목표이다.
텍스트와 이미지 크롤링의 방식을 배우고자 한다.
파이썬은 구름IDE(Integrated Development Environment, 통합개발환경)을 사용하여 실행하려 한다.
구름 IDE는 내 PC에 파이썬 등의 설치 및 환경설정을 하지 않고도 개발과 코드를 작성할 수 있다.
쉽게 말해 클라우드 기반 서비스라고 생각하면 된다.
아래에 사이트에 접속하여 사용할 수 있다.
구름 IDE에서 하려 했으나....
컨테이너 생성이 되지 않고, 강의도 꽤 오래된 내용이라. 강의는 참고로 사용하고, 그냥 하나하나 부딪혀봐야겠다.
파이썬 개발환경부터 내 PC에 설치해야겠다.
파이썬 개발 환경 설치
1. 우선 파이썬을 설치해야 한다.
Welcome to Python.org
The official home of the Python Programming Language
www.python.org
홈페이지에서 다운로드할 수 있다.
파이썬 공식 홈페이지에서 DOWNLOADS > DOWNLOAD FOR WINDOWS 버튼을 눌러준다.

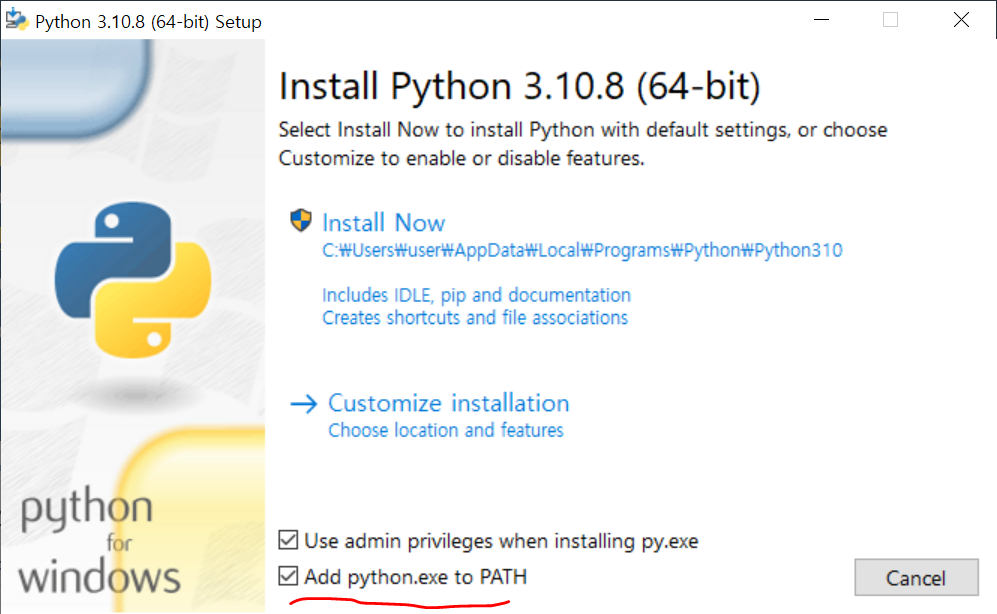
Add python.exe to PATH를 체크해주고 설치를 진행한다.

2. vsCode를 실행한다.
만약 설치가 되어있지 않다면 아래 홈페이지에서 다운로드할 수 있다.
https://code.visualstudio.com/
Visual Studio Code - Code Editing. Redefined
Visual Studio Code is a code editor redefined and optimized for building and debugging modern web and cloud applications. Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows.
code.visualstudio.com
3. 파이썬을 실행할 폴더를 하나 만들고 Visual Studio Code에서 열어준다.
나는 crawling 폴더를 만들었다.
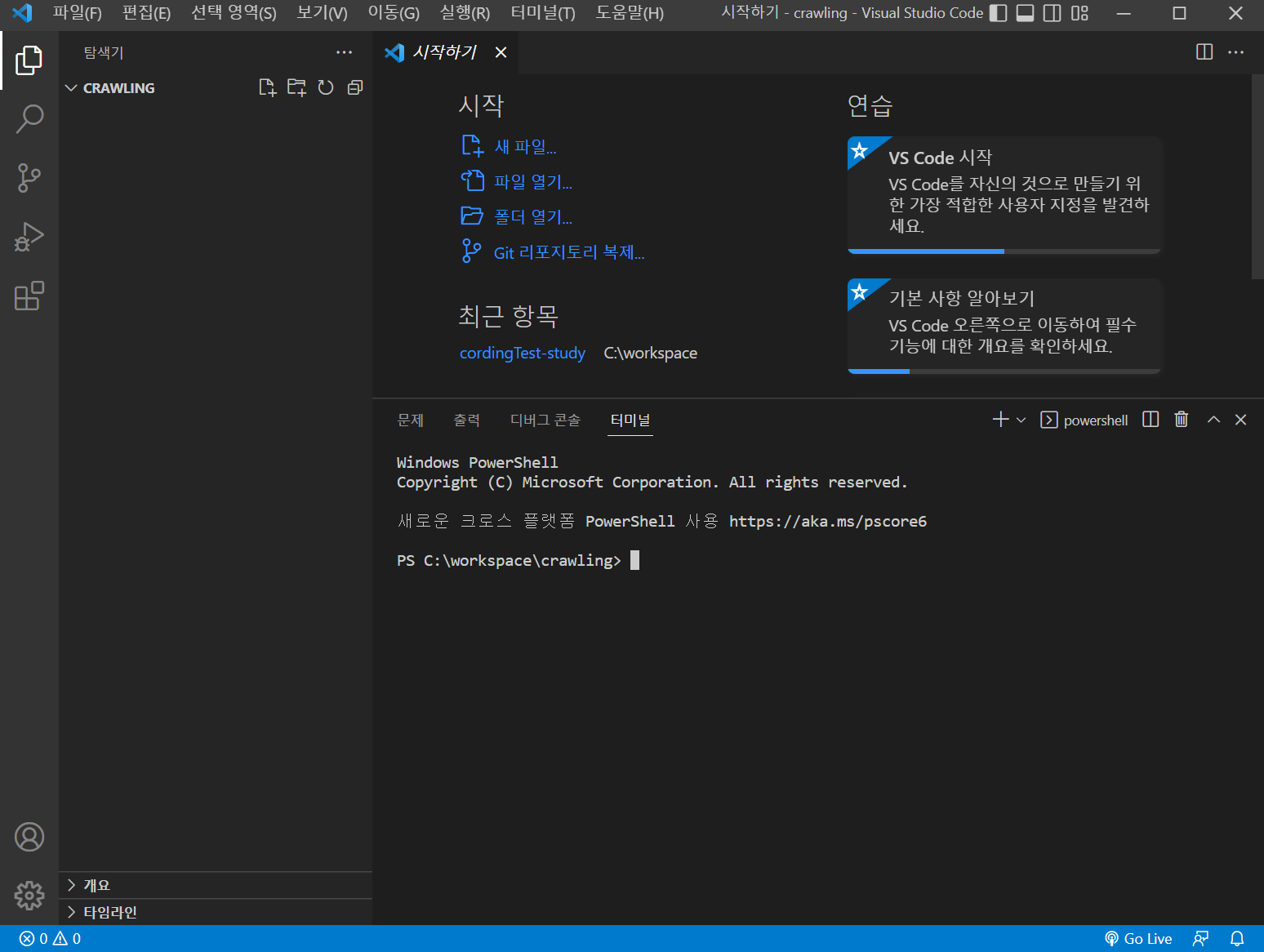
4. "app.py"라는 파일을 하나 만들어준다. 그리고 아래와 같은 내용을 추가한다.
나는 "Hello, World"를 출력해 보겠다.
터미널 창을 열고 (터미널 창이 없다면 Ctrl + `을 사용하여 열면 된다.)를 입력해준다.
python app.py
그러면 다음과 같이 Hello, world 가 출력되는 것을 볼 수 있다.
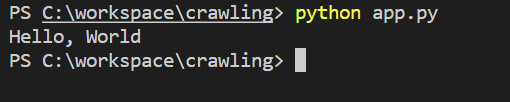
"Hello, World"를 출력하였다면 이제 반은 한 것이다.
파이썬으로 크롤링하기
크롤링은 웹 페이지를 그대로 가져온 다음 데이터를 추출하여 사용할 수 있는 행위이다.
크롤링을 하기 위해 beautifulsoup 라이브러리를 사용하겠다.
beautifulsoup 은 HTML과 XML구문을 분석할 수 있는 파이선 패키지(라이브러리)이다.
1. beautifulsoup 사용하기
https://ko.wikipedia.org/wiki/뷰티플수프
뷰티풀 수프 (HTML 파서) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전.
ko.wikipedia.org
뷰티풀 수프 위키백과에 나와있는 예제로 사용을 해보겠다.
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))다음과 같은 코드를 app.py에 붙여 넣어준다.
그리고 "python app.py" 명령어로 실행시켜주면, 다음과 같은 내용이 보인다.

bs4라는 모듈이 없다 하니 모듈을 설치해주자
2. beautifulsoup4 모듈 설치하기
다음과 같은 명령어로 beautifulsoup4 모듈을 설치해준다.
pip install bs4
다음과 같이 설치가 완료된다. npm 패키지 라이브러리의 개념으로 생각하면 된다.
3. app.py 실행하기
"python app.py" 명령어로 실행을 해주면
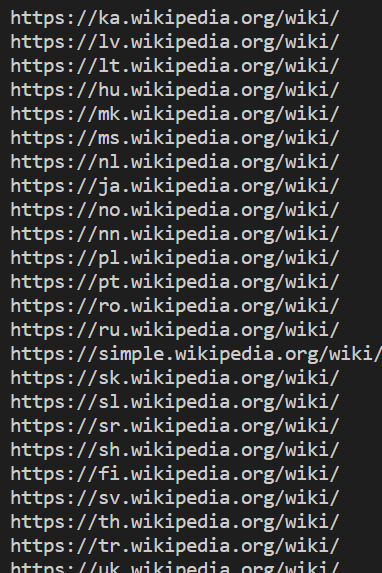
이와 같은 url들을 크롤링한 것을 볼 수 있다. 코드를 보면 주석에 설명을 달아 놓았다.
app.py
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 이 url에서 response라는 곳으로 담는다.
# response = urlopen('https://en.wikipedia.org/wiki/Main_Page') 과 같은 내용이다.
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
#response를 soup 변수에 넣겠다.
soup = BeautifulSoup(response, 'html.parser')
#for문이다. find_all <a>태그의 주소를 가져와서 출력해준다.
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))
더 자세한 사용법은 beautifulSoup 공식문서에 도큐먼트를 보면 된다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
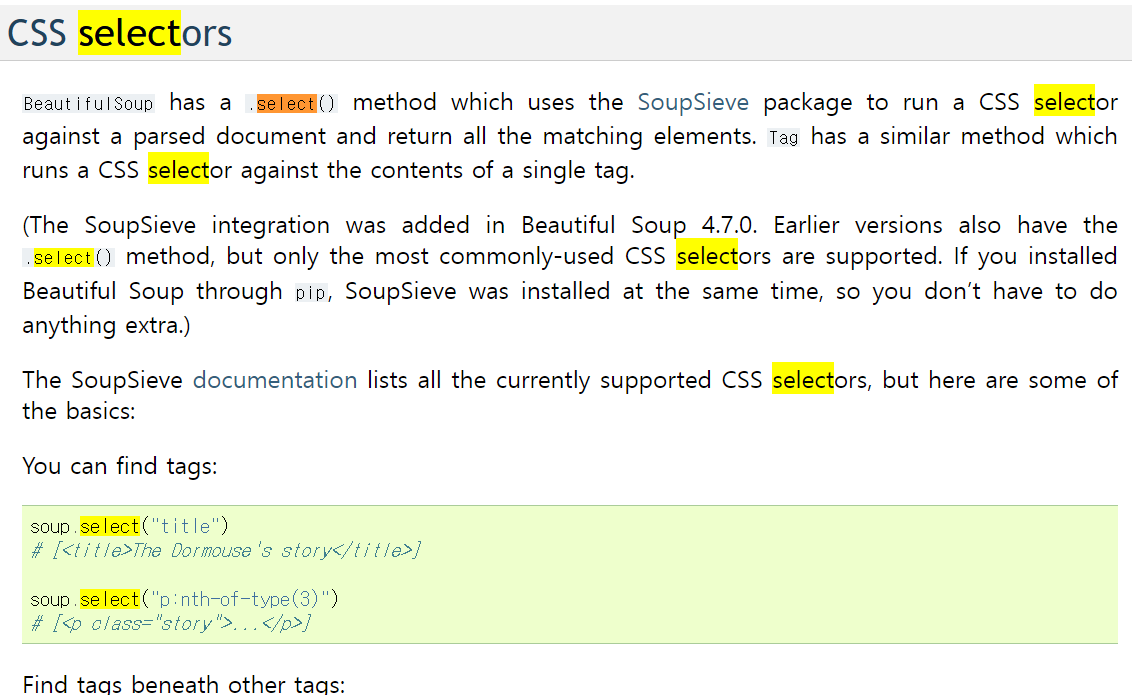
내리다 보면 CSS selectors가 있는데 이 안에 있는 함수를 주로 많이 사용하게 된다.
CSS 선택자와 비슷하다.
4. 응용하기
나는 네이버 헤드라인 뉴스의 기사의 타이틀을 크롤링해보겠다.
네이버 헤드라인 뉴스를 개발자 도구를 켜서 보면
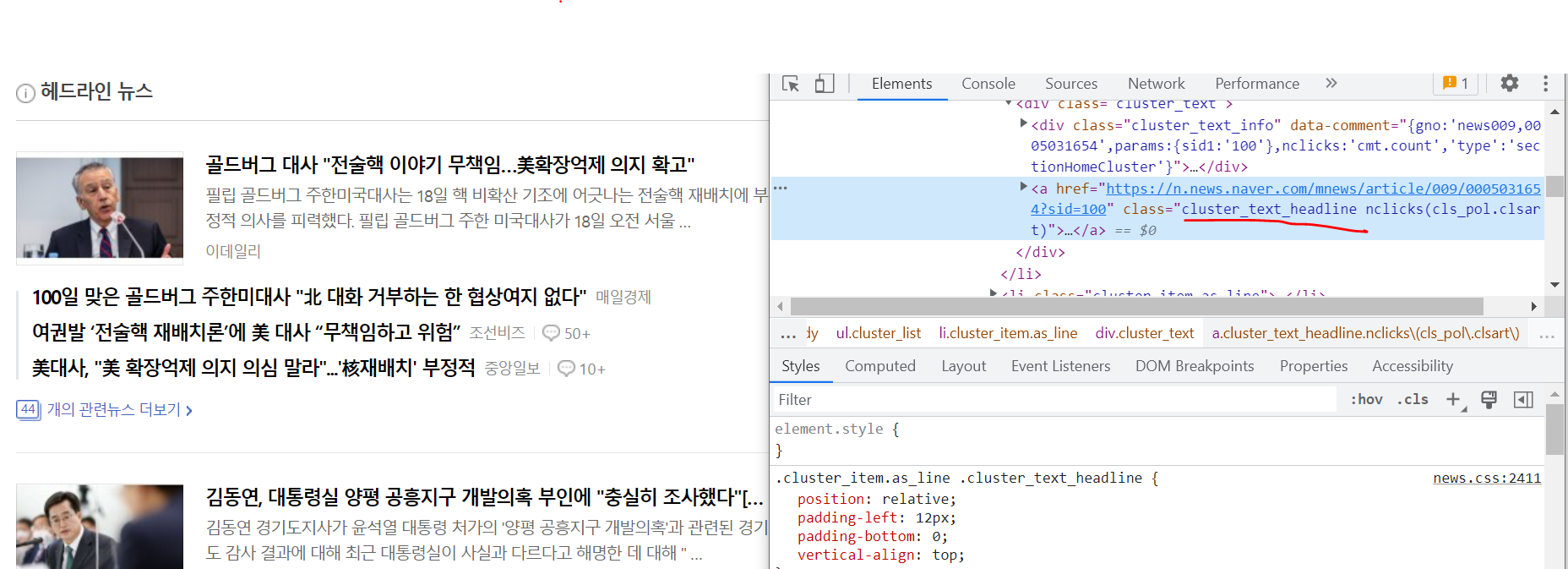
헤드라인 기사들은 cluster_text_headline이라는 클래스를 사용하는 것을 볼 수 있다.
나는 crawling.py라는 파일을 하나 더 만들고 코드를 다음과 같이 작성하였다.
crawling.py
#crawling.py
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 이 url에서 response라는 곳으로 담는다.
# 자신이 크롤링할 url로 변경해준다. 나는 네이버 뉴스로 url을 변경해주었다.
with urlopen('https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100') as response:
soup = BeautifulSoup(response, 'html.parser')
#이부분을 네이버 헤드라인 타이틀 클래스인 .cluster_text_headline 으로 바꾸어준다.
for anchor in soup.select('a.cluster_text_headline'):
print(anchor)python crawling.py 명령어로 실행을 하면 다음과 같이 크롤링해 온 것을 확인할 수 있다.
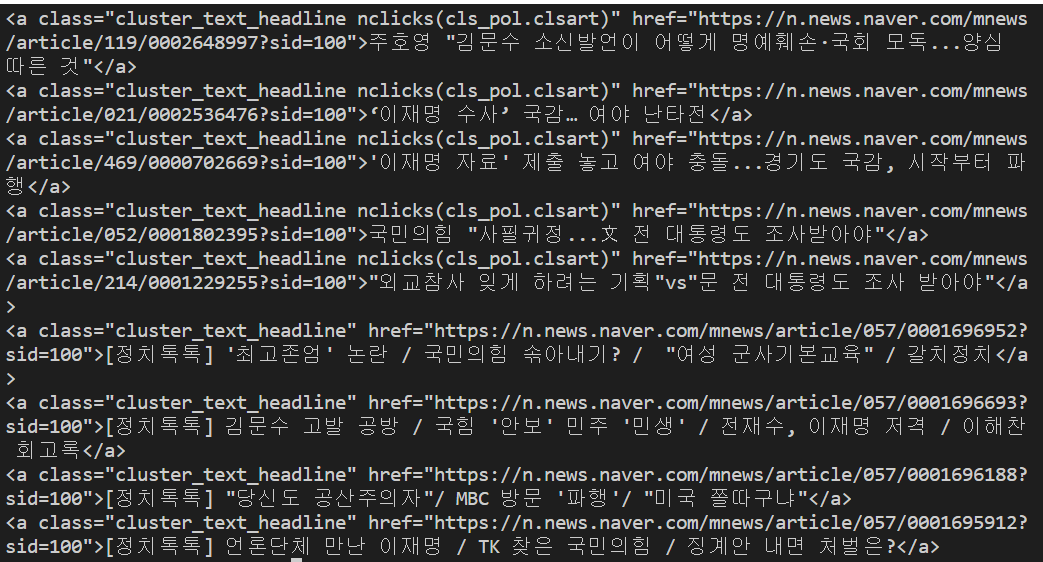
그리고 print 코드 부분을 get_text() 함수를 사용하여 바꾸면 텍스트만 가져올 수도 있다.
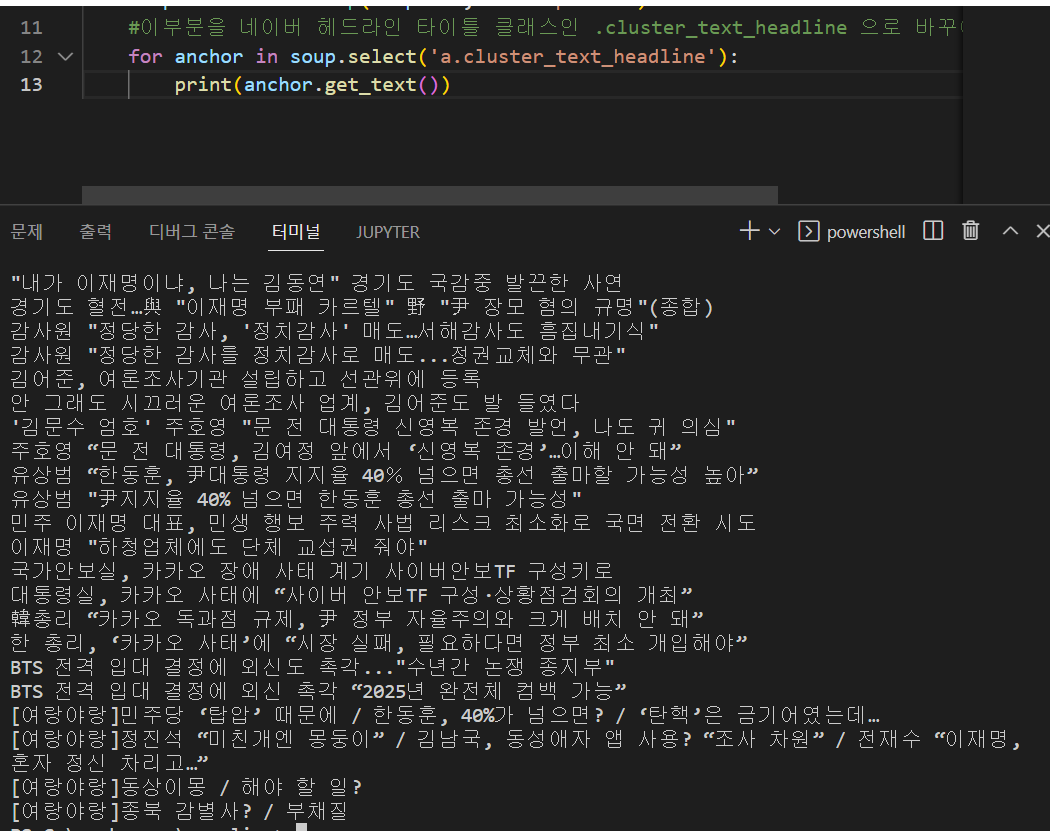
5. 텍스트 파일로 저장하기
crawling.py를 다음과 같이 변경해준다. 추가된 코드는 파일을 저장하는 코드이다.
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 이 url에서 response라는 곳으로 담는다.
# 자신이 크롤링할 url로 변경해준다. 나는 네이버 뉴스로 url을 변경해주었다.
with urlopen('https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100') as response:
f = open("C:/workspace/crawling/새파일.txt", 'w', encoding="UTF-8")
i = 1
soup = BeautifulSoup(response, 'html.parser')
#이부분을 네이버 헤드라인 타이틀 클래스인 .cluster_text_headline 으로 바꾸어준다.
for anchor in soup.select('a.cluster_text_headline'):
data = str(i) + " : " + anchor.get_text() + "\n"
i = i + 1
f.write(data)
f.close()
위의 예제를 사용하면 아래와 같이 새 파일. txt 파일이 생성되며 크롤링한 데이터가 추가된다.
원래는 데이터가 깨져서 나와서 f = open () 함수에 encoding="UTF-8"을 붙여주었다.
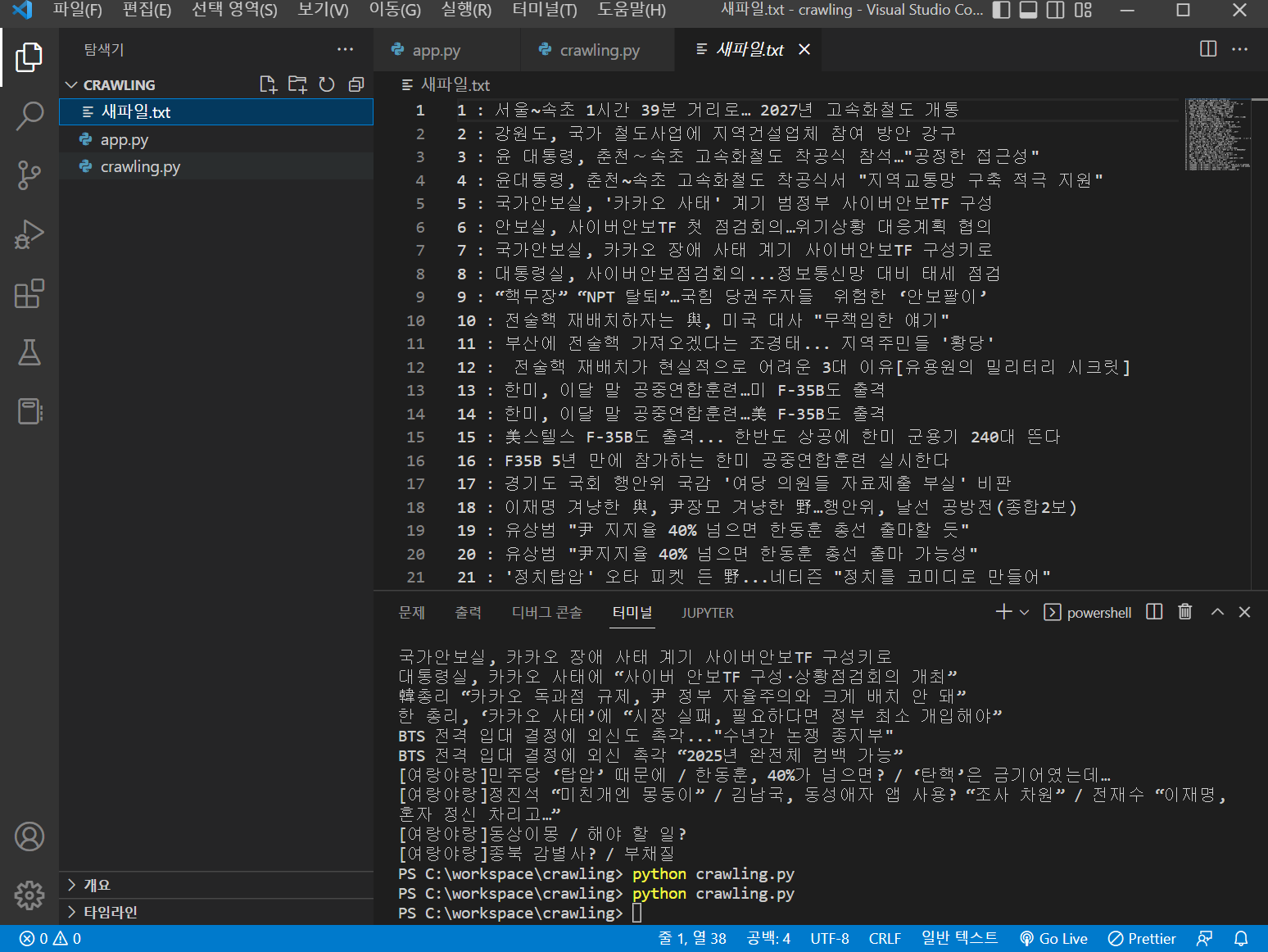
6. 구글 이미지 크롤링 라이브러리 다운
다음과 같은 명령어로 구글 이미지 크롤링 패키지를 설치해준다.
pip install google_images_download
https://pypi.org/project/google_images_download/
google_images_download
Python Script to download hundreds of images from 'Google Images'. It is a ready-to-run code!
pypi.org
해당 라이브러리 사이트이다.
"image.py"를 새로 만들어주고 다음과 같은 해당 라이브러리 도큐먼트에 있는 예제를 복사해준다.
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True} #creating list of arguments
paths = response.download(arguments) #passing the arguments to the function
print(paths) #printing absolute paths of the downloaded images
"python image.py"로 실행해준다.
실행 했더니 폴더는 생겼는데 이미지를 다운로드할 수 없었다.
오류 발생
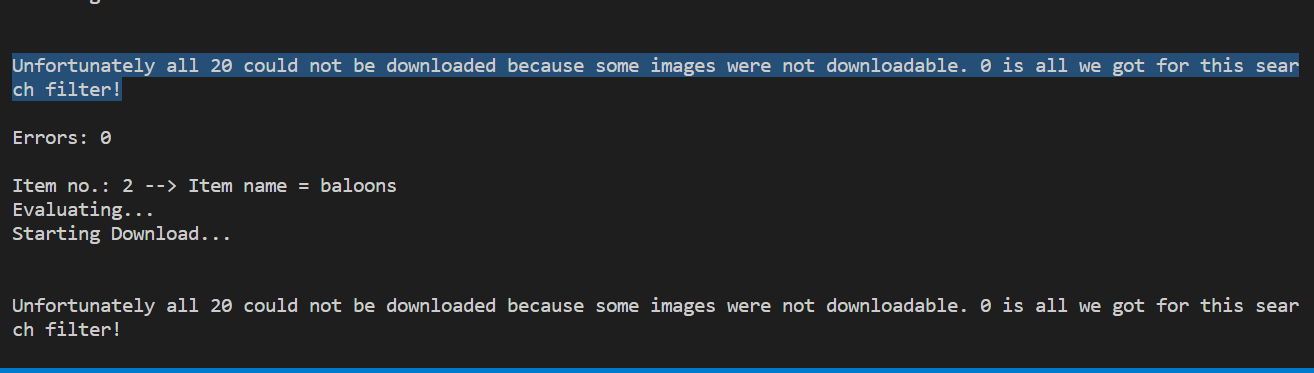
Unfortunately all 20 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter! 키워드로 검색해보니
다음과 같은 명령어로 해결할 수 있었다.
1. 기존 google_images_download 라이브러리 삭제
pip uninstall google_images_download2. 수정된 패키지 설치
pip install git+https://github.com/Joeclinton1/google-images-download.git
3. 다시 실행
정상적으로 이미지를 크롤링한 것을 볼 수 있다.
위의 해당 image.py예제에서와 같이 keyword와 limit를 변경해주면 자신이 원하는 검색어에 대한 이미지들을 다운로드할 수 있다.
파이썬 크롤링을 처음 해보았는데 은근 재미도 있고, 어렵지 않은 것 같다.
이제 크롤링을 사용하여 데이터를 가져올 수 있고, 이 크롤링한 데이터들로 나만의 인공지능 웹 앱을 만들 수 있다.
'개발 공부 시리즈 > 수익형웹앱만들기' 카테고리의 다른 글
| 안드로이드 스튜디오 다운로드 및 환경 설정 (0) | 2022.11.08 |
|---|---|
| 수익형 웹&앱만들기 기본지식 (2) - 파이썬 셀레니움(Python Selenium) (0) | 2022.10.20 |


댓글